GPT-Load
综合介绍
GPT-Load是一个为企业和开发者设计的高性能AI接口代理服务。它使用Go语言开发,专门用来统一管理和调用多种AI大模型服务的接口,比如OpenAI的GPT系列、谷歌的Gemini以及Anthropic的Claude。这个工具的核心功能是作为“中间人”,开发者可以将所有对不同AI服务的请求都发送给它,它再根据设置好的规则,使用密钥池中的密钥去请求真正的AI服务。它支持智能的密钥管理,可以自动轮换、处理失效的密钥,还能将请求分发给多个服务器,实现负载均衡,确保服务稳定可靠。此外,它还提供了一个基于Vue 3的网页管理后台,让用户可以直观地查看请求日志、管理密钥和调整系统设置。
功能列表
- 透明代理:完全兼容OpenAI、Google Gemini和Anthropic Claude等多种AI服务的原生API格式,迁移应用时几乎不需改动代码。
- 智能密钥管理:支持将API密钥分组管理,可以设置多个密钥并自动轮流使用。当某个密钥失效时,系统会自动将其拉黑并换用其他可用密钥。
- 负载均衡:支持配置多个上游API服务端点,并按权重分配请求流量,提高服务的整体可用性。
- 动态配置:系统的大部分设置和密钥分组配置支持热重载,修改后无需重启服务即可生效。
- 企业级架构:支持分布式的主从节点部署模式,可以通过增加节点来水平扩展服务能力,保证高可用性。
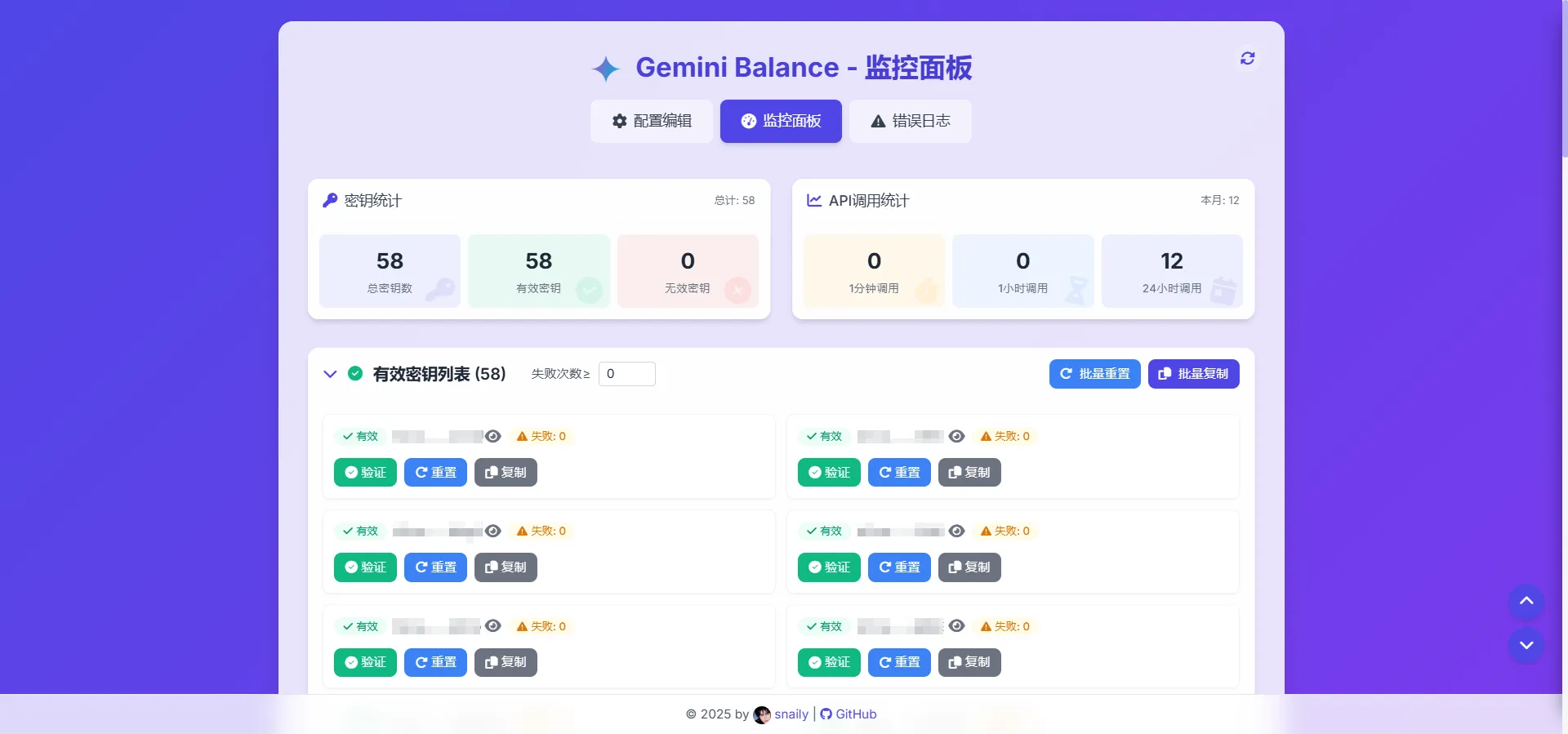
- Web管理界面:提供一个基于Vue 3开发的现代化Web管理后台,用户可以方便地查看实时统计、管理密钥、查询请求日志。
- 全面监控:内置实时的数据统计、服务健康检查和详细的请求日志记录功能。
- 高性能设计:后端采用Go语言开发,通过流式传输、连接池复用等技术优化性能,专为高并发的生产环境设计。
使用帮助
GPT-Load的设计目标是简化多AI服务接口的管理和调用流程。通过将所有API请求指向GPT-Load代理,开发者可以实现统一的密钥管理、负载均衡和故障切换。以下是详细的使用流程。
安装部署
推荐使用Docker Compose进行安装,这种方式最简单,也便于管理。
环境要求:
- Docker
安装步骤:
- 创建并进入项目目录打开终端,输入以下命令来创建一个名为
gpt-load的文件夹并进入该目录。mkdir -p gpt-load && cd gpt-load - 下载配置文件使用
wget命令下载docker-compose.yml和.env配置文件。wget https://raw.githubusercontent.com/tbphp/gpt-load/refs/heads/main/docker-compose.yml wget -O .env https://raw.githubusercontent.com/tbphp/gpt-load/refs/heads/main/.env.example ``` `.env`文件包含了服务的默认配置,比如端口和初始管理员密钥。 - 启动服务执行以下命令,Docker Compose会自动拉取镜像并以后台模式启动服务。
docker compose up -d默认配置下,服务会使用SQLite作为数据库,适合轻量级单机部署。如果需要连接MySQL或PostgreSQL,可以修改
docker-compose.yml文件,将相应服务的注释取消,并在.env文件中配置好数据库连接信息后重新启动。 - 验证安装部署完成后,可以通过以下地址访问服务:
- Web管理界面:
http://localhost:3001 - API代理地址:
http://localhost:3001/proxy
打开浏览器访问Web管理界面,使用
.env文件中AUTH_KEY配置的默认密钥sk-123456登录。 - Web管理界面:
功能操作流程
登录Web管理界面后,核心操作是创建分组、添加密钥和调用代理接口。
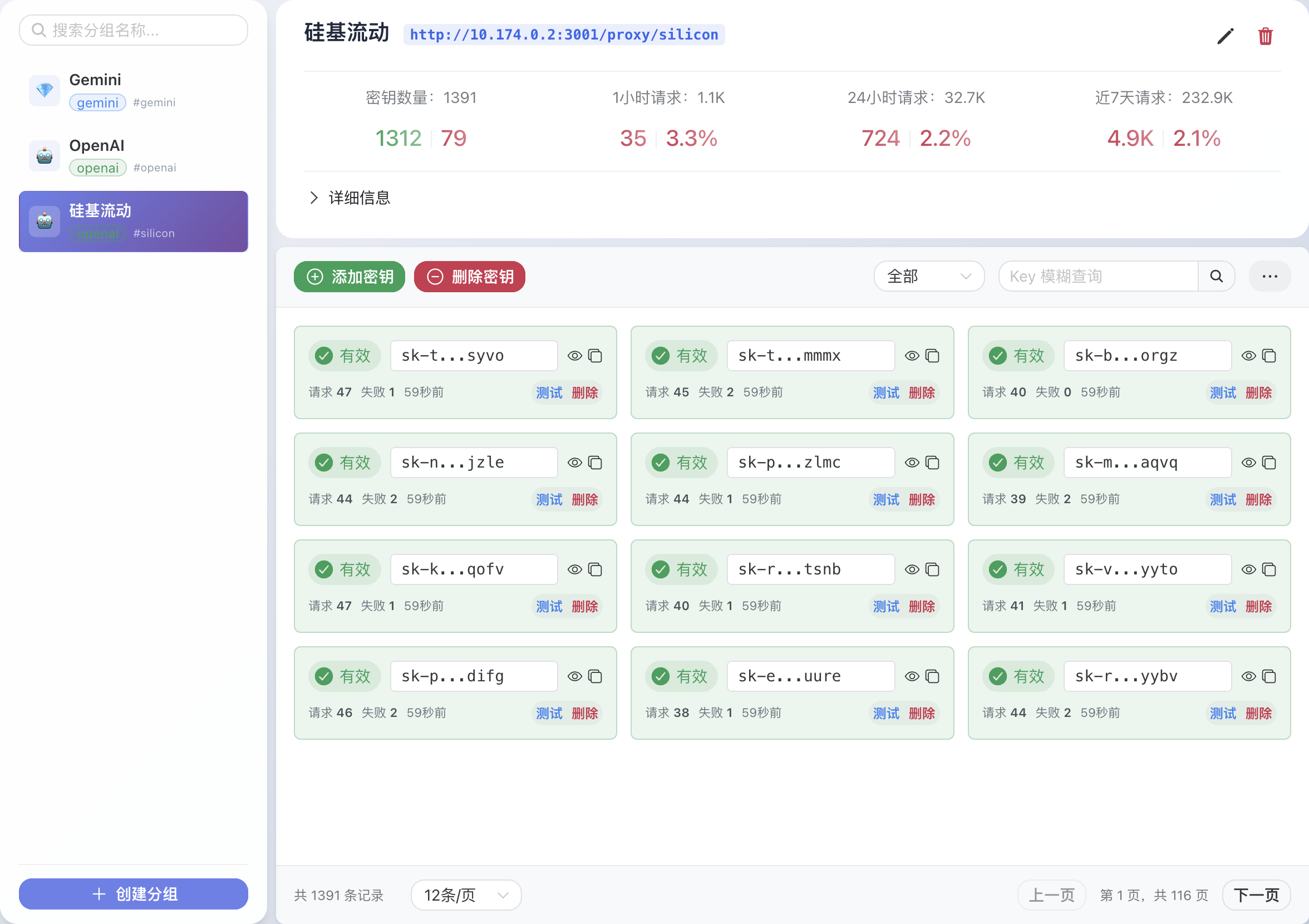
第一步:创建分组
分组用于管理不同AI服务或不同业务场景的API密钥。
- 在左侧导航栏点击“密钥管理”。
- 点击“新增分组”按钮。
- 填写分组信息:
- 分组名称:一个易于识别的英文名,比如
openai或gemini-marketing。这个名称将用在API的URL中。 - 上游端点:填写真实的AI服务API地址,多个地址用逗号隔开。例如,OpenAI的地址是
https://api.openai.com。 - 备注:可选,用于描述分组用途。
- 分组名称:一个易于识别的英文名,比如
- 点击“保存”,完成分组创建。
第二步:添加API密钥
为刚刚创建的分组添加真实的AI服务API密钥。
- 在“密钥管理”页面,找到目标分组,点击“管理”按钮。
- 点击“新增密钥”按钮。
- 将你的AI服务商提供的API Key粘贴到输入框中,支持批量添加(每行一个)。
- 点击“保存”。GPT-Load会将这些密钥保存在一个密钥池中,用于轮询调用。
第三步:配置代理密钥
为了安全,我们不直接使用原始密钥调用代理,而是设置一个新的“代理密钥”来访问GPT-Load。
- 在左侧导航栏点击“系统设置”。
- 找到“全局代理密钥”(
proxy_keys)字段。 - 输入一个或多个自定义的密钥,例如
my-secret-proxy-key-1,多个密钥用逗号分隔。 - 点击页面底部的“保存”按钮。这个密钥就是之后应用代码中用来调用GPT-Load代理的密钥。
- 你也可以在每个分组的配置中单独设置分组级别的代理密钥,其优先级高于全局代理密钥。
第四步:调用代理接口
现在,你可以在你的应用程序代码中,将原始的API请求地址和密钥替换为GPT-Load的代理地址和代理密钥。
以OpenAI Python SDK为例:
- 原始调用方式:
from openai import OpenAI client = OpenAI( api_key="sk-your-openai-key", # 你的OpenAI Key ) - 使用GPT-Load代理的调用方式:假设你创建的分组名为
openai,配置的代理密钥为my-secret-proxy-key-1。from openai import OpenAI client = OpenAI( api_key="my-secret-proxy-key-1", # 使用你在GPT-Load中设置的代理密钥 base_url="http://localhost:3001/proxy/openai" # 指向GPT-Load的代理地址,路径末尾加上分组名 ) # 后续代码保持不变 response = client.chat.completions.create( model="gpt-4.1-mini", messages=[{"role": "user", "content": "Hello"}] ) print(response.choices[0].message.content)
通过以上步骤,你的应用请求就会先经过GPT-Load,由它负责从密钥池中选择一个有效的密钥去请求OpenAI,然后将结果返回给你的应用。你可以在Web界面的“请求日志”中看到详细的调用记录。
应用场景
- 多模型服务统一管理对于需要同时使用OpenAI、Gemini和Claude等多种大模型服务的应用,开发者无需在代码中管理多个SDK和密钥。只需将所有请求指向GPT-Load,即可通过不同的分组路径调用相应的模型,简化了应用的配置和代码复杂度。
- API密钥的安全与成本控制企业可以将大量的API密钥存放在GPT-Load的密钥池中,并设置代理密钥给开发团队使用。这样可以避免原始密钥在代码中暴露,同时通过轮询和负载均衡,将请求分散到多个密钥上,避免单个密钥因超出速率限制或额度耗尽而导致服务中断。
- 提高服务可用性当某个API密钥或某个上游服务端点出现故障时,GPT-Load的智能故障处理机制会自动将该密钥或端点加入黑名单,并将后续请求无缝切换到其他可用的密钥或端点上,从而保证了服务的连续性和稳定性。
- 开发与生产环境隔离可以为开发、测试和生产环境部署不同的GPT-Load实例或设置不同的分组。例如,开发环境可以使用免费额度的密钥进行测试,而生产环境则使用付费的高额度密钥,切换环境时只需修改应用配置中的代理地址和密钥即可。
QA
- GPT-Load和AI模型本身有关系吗?比如OpenAI的GPT?没有直接关系。GPT-Load是一个API代理和管理工具,它不提供任何AI计算能力。它名字中的“GPT”只是项目命名的一部分,其核心功能是管理和转发对OpenAI GPT、Google Gemini等各种AI服务的API请求。
- 如果我添加的某个API密钥失效了,会发生什么?GPT-Load在转发请求时,如果发现某个密钥连续多次请求失败(失败次数可配置),会暂时将该密钥放入“黑名单”,并在后续请求中自动跳过它,选用其他可用密钥。系统还会定期检查黑名单中的密钥是否恢复正常。
- 使用GPT-Load会影响API的响应速度吗?GPT-Load本身是使用高性能的Go语言开发的,并且采用了流式传输和连接池等优化手段,引入的延迟非常低。在绝大多数情况下,这点额外的网络开销对整体响应时间的影响可以忽略不计,但它带来的密钥管理和高可用性优势远超这点开销。
- 它支持哪些AI服务商?它采用透明代理模式,理论上可以支持任何提供与OpenAI、Google Gemini或Anthropic Claude API格式兼容的服务。这意味着除了官方服务,一些第三方的兼容API服务也可以通过GPT-Load进行代理。